
“A good strategy always starts with reflection on your current situation,” Christopher Brossman, director of data engineering at The RealReal, said. “You need to be honest about what you’ve built so far and what gaps exist in order to make a plan to execute on your vision.”
Brossman is talking about MLOps, a subject in which he is a particularly strong advocate.
“MLOps is needed now, more than ever, as companies transition from using machine learning in an exploratory way to using it as a core operational software component to deliver value.” If MLOps is not utilized, Brossman said, there might be significant delays or even derailments.
Statistics back up his claims. According to deeplearning.ai, there is currently an enormous deployment gap when it comes to software teams using machine learning, and only 22 percent of companies using ML have successfully deployed a model.
Brossman believes MLOps is the answer to that deployment gap, and we sat down with him for an in-depth take on why MLOps is so important and how it can best be utilized.
For those unfamiliar, what exactly is MLOps?
MLOps combines elements of machine learning and DevOps to enable machine learning models to be easily trained, deployed and monitored. MLOps is not a separate discipline from DevOps, but rather the extension of its principles to enable machine learning to work seamlessly in production.
Why should companies consider using MLOps?
MLOps is still a bit new. Tooling and best practices are changing rapidly, just like the field of machine learning. Just as software needs to be battle tested and well maintained, so too do ML models and pipelines. If you scale your ML team up without focusing on MLOps technologies, you’ll find yourself slowing down due to inefficient work flows, deployment lags and piling tech debt.
Indicators That It's Time to Invest in MLOps
- Inefficient workflows: every step is manual or done with custom code, from data extraction to data cleaning to model building to deployment
- Code is copied between projects (or just re-written) instead of sharing “common steps” or a common repo
- Long ramp-up time on tooling when ML engineers switch projects
- Deployment lags that involve multiple teams
- Takes weeks to retrain models
- Scaling issues: training is blocked by multi-day data transformations
- Tech debt: being locked into a simpler model type due to your deployment pipeline
- Lineage and traceability: when deployment breaks, it’s not easily to tell where the failure occurred
What are some of the challenges in using an MLOps strategy?
It should be evident by now why MLOps is useful, but you may be asking yourself why solid MLOps strategies aren’t more prevalent, or at least as prevalent as solid DevOps strategies.
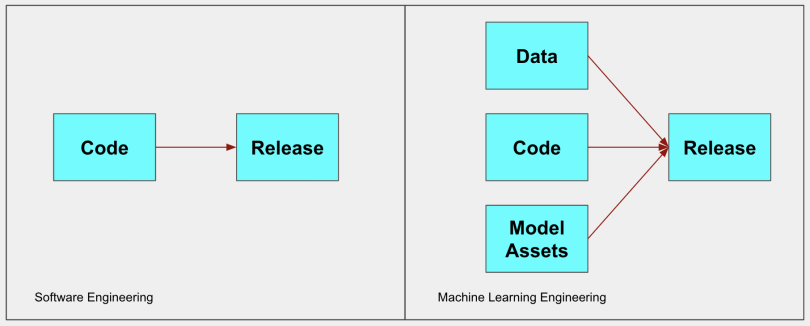
With traditional DevOps and software engineering, the code isn’t dependent on the data. With machine learning, a change in data drastically impacts the quality of predictions — the code, data and model are all interconnected. Given these additional dependencies, MLOps requires different tooling than DevOps to ensure successful releases. A DevOps toolkit includes CI/CD, audit logs, repo integration and alerts. An MLOps toolkit should include all those plus tools like an ML pipeline trainer and orchestrator, model registry, model monitoring and feature store.
If you are deploying a myriad of different types of models, using different data sources and different ML design patterns and working with different SLAs, it is currently impossible to find one tool that can do it all without customization or extension. Today, you’ll find that you need to piece together a few tools that can give a reasonably complete solution in any situation. But beware of tool proliferation and tight integration with any one tool, because in just a few years the landscape will drastically change once again.
How can companies implement an MLOps strategy?
Once you’ve identified the major pain points, you’ll need a process that can identify if those pain points are best solved with people, process or technology.
If resources allow, I’d recommend hiring a dedicated MLOps architect, who can solely focus on the relentless pursuit of the perfect pipeline and common core repo. This may be a large effort with many deliverables and change management, so you need to make sure this member is well equipped to lead change. MLOps is a multiplier to your whole ML org, and the more people you have on your team, the bigger the impact will be.
When you get above 10 people whose job it is to build models and put them into production, it’s time to start thinking about the ML architect role. Also think about your partnership with DevOps, as this role spans both orgs and requires close partnership. Furthermore, consider integrating with the existing ML engineers that have worked in a variety of industries with different deployment patterns and cloud solutions as part of the MLOps review panel. Create a process that can be used to review new technologies that is open to change, but has a rigorous data driven selection process.
For technology, you’ll want to ensure you have tooling that supports reusable components for your pipelines. Some common examples include: data generation, calculating statistics on the distribution of that data, transforming the data for the model, training, evaluation and deploying. All these steps create your model pipeline which can be individually adjusted, deployed and tested. The automation at this stage enables CT (continuous training) on your pipeline, which, when paired with CI/CD makes for excellent durability.
Some popular frameworks in this area are Kubeflow and TFX. When evaluating infrastructure, opt for serverless solutions (if doing it yourself). Serverless solutions are usually cost-effective because you pay for what you use, while having the benefit of scale. In addition, there is no need to manage the underlying infrastructure, so it’s pretty turnkey.
Pay attention to how you plan to have your models called in production. Some options include: batch, synchronous web applications, event driven web applications, in browser models and models on device. The more options you have, the more complex/custom your MLOps solution will need to be.
I am a big fan of event-driven applications paired with serverless infrastructure.”
Watch out for training-serving skew. This one can be a real pain to debug, but can be mitigated with a few common patterns. One mitigation strategy is to do the transformations within the model-graph itself. If these transformations are tied to the graph, the transformation is guaranteed to be the same in training and serving. This works great for static data, such as images, but falls short for windowed inference pipelines. For these types of pipelines, the training and serving infrastructure may require different tools. One way to lessen the training-serving skew in this situation is with a feature store, which handles both feature cataloging, as well as serving for both training and inference.
When doing gap analysis, don’t underestimate the need to handle data and model lineage. Extending other ML engineers’ code and ML models can be a nightmare when inheriting a project without a way to recreate the production model which requires a specified version of code, configuration and dataset. These lineage tools automate this process to effectively store everything you need to recreate all of your experiments.


